
Detecting Objects from Aerial Images (1)
Published:
This article is about a project I did at the ISP at the University of Stuttgart. The goal was to program a model and algorithm that detects & segments trees on a statewide scale in Southern Germany. While our focus is on the village areas, cities and forests should also achive feasible results. This article is split in two parts, the first one focuses on the development of the detection model and framework. In the second part I examine how this framework can be adapted to other targets, such as solar panel detection.
Tree Detection
In the first post I talk especially about the training of the tree prediction models. There will be another part about transferability.
First Approaches and initial Requirements
Each Tree should be identified with a Centroid, a Mask, Crown Diameter and height data. Furthermore the algorithm should be performant enough to handle several thousand square kilometers completely automatic. We are supplied with approximately 10.600 bounding box annotations of single tree crowns in the village area. Additionally we can use several modalities: (1) RGBI-DOPs so color images, that also have a forth channel that includes Near-Infrared Data and are orthorectified and true to scale. Each of this images also contains metadata with the correct positions in EPSG:25832 and resolution, correct to a few centimeters. (2) Digital terrain model a smooth strucutre model that presents the surface of the earth at the ground level (3) Digital surface model a model that contains the effective surface, so including the buidings and in key also vegetation and (4) normalized Digital Surface Model the differece between (2) and (3), so every elevation from ground level, such as buildings, constructions, infrastructure and vegetation.
This poses a set of questions at the start:
- How much open-data training annotations can be found online?
- What modalities can be used in our pipeline?
- What exactly should our model predict?
These questions will be answered throughout the article.
Similar Projects
Trees are essential for enviorment science and urban planning, so of course there are a lot of datasets and software we can take inspiration from.
DeepForest A Inference Framework trained on US-Forest data that is especially strong in its resource efficiency and strong inference skills in boreal forest areas. It predicts bounding boxes. A first try resulted in a Accuracy of 0.3 on the provided annotations.
Detectree2 A Python Package for detection and tree delineation, based on the Mased-RCNN architecture of Meta, that focuses not only on extracting bounding boxes but also segmenting a closed shape from it. The model was mainly developed for jungle regions in the area of borneo. Interestingly there is an adaption to the Cambridge-Area for a master thesis that shows good results in contrast to the original model.
Some other models, that could also be interesting include a report published by the ETH-Zürich or the summaries listed in a meta-study. Notably most of these models are either orchards or forest environments. It is harder to find any good inference models for urban areas.
Data Availability
While we have enough raw data, there is a scarcity on good tree annotations, this is mainly due to the difference in vegetation of different world regions, the high effort of annotating dense regions (we needed apx. 8 hrs for 0.25 qkm of forest) and the ambiguity in aerial imagery. Datasets that exist include:
- ShadowSense A Mixed Unsupervised Algorithm to Detect Trees from RGB and Thermal data containing the RT-Trees Dataset
- OpenForest A Meta-Colllection over 90 datasets, some of them containing RGB imagery.
- The Millon Trees Project Again a Meta-Collection with over one million trees, that by now includes trees that could be used in our project, including good polygons and box annotations.
- NEON Tree Crowns Dataset Estimations for 100 Million trees at 37 Sites in the United States, each done with DeepForest, so it should not provide us more information or cover the domain shift from coniferous and boreal forest to the mixed European forests. Moreover there is a high number of incomplete land registers contianing communal or county trees, but not private trees, so the training possibilities with them are also limited.
First Results and Pipeline
Firstly we tried the already existing Frameworks of DeepForest and Detectree2, we found both frameworks not suitable out-of-the box for our goals, so we focused on finding the right model first. We looked at several detection and segmentation mechansism such as YOLOv5, Faster R-CNN, Mask R-CNN or SegFormer. Overall we decided on using a Mask R-CNN architecture, since on the one hand we think transformers are too complex to train and infer, but YOLO might be too limited. Additionally Mask R-CNNs provide us with correct shapes. At the start we prototype with the Detectree2 architecture as it also uses Mask R-CNNs and has good mechansims to handle the geospatial data. The architecture consists of a Region Proposal Network and two heads to further analyze the regions identified, one to sement the object and a second to infer a class in our case tree, with a certain probability:
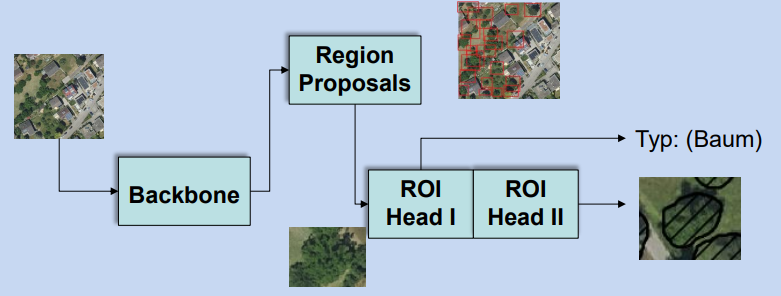
The Masked R-CNN architecture in example of tree data.
Naively training with initally given 4.000 Bounding Boxes does not provide a good result and also retraining using already existing models does not give good results, so with time we came up with this pipeline:
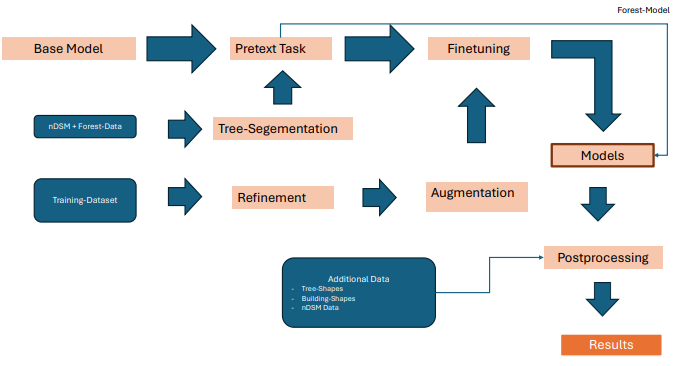
The initial pipeline populated with the final data supplementaries at each state.
Refinement of Training Annotations
Since we only work with Bounding Box Data one approach to get better inference results would be to refine the training data. This means to somehow segment the crowns as polygons from the bounding boxes. Since we do not want to do this manually, as this might be useful later on we focus on making this also automatically. We use Samgeo, a geospatial version of Segment Anything, to firstly get an inital proposal for a shape. Afterwards we use the informations given by the correct bounding box and compute indicators such as IOU and Containment to assess the feasibility of the crown and if necessary repair it thorugh clipping. These parameters are finetuned on another dataset that contains polygons.

Examples of how the bounding boxes are segmented to crowns (green) and then postprocesed (black).
Filtering
We also begin introducing a postfiltering algorithm, this is mainly due to one insight: “Confidence Filterung and Non-Maxima Suppresion is not enough, even if trained perfectly”. This is due to the structure of Masked R-CNN models and the use case we have, here single crowns could be seen as there is the ambigous case of detecting part of a tree vs. two trees close by each other:
During the development we found several good working heuristics:
- Confidence Score The Confidence Score directly produced by ROI Head 1, represents the fidelity of the model in the instance and low confidence directly indicate a worse prediction
- Height A Height threshold helps to distinguish bushes and other vegetation from trees since we only want to consider trees above 3m
- NDVI-Index The Normalized Difference Vegetation Index indicates the difference between the red and the near-infrared channels. This is used to further remove firstly trivial false predictions for instance on buildings or streets as well as small vegetation.
- Containment Since the most critical parts are hierachical predictions we also have to find a good heuristic to select right and wrong examples. We use several combined steps utilizing Confidence, Height, Centroid and NDVI in order to filter most polygons.
- Exclusion There are some trivial Geometries such as rivers, buildings or lakes that can be excluded - Here the challenge is not only to exclude them, but to do so efficiently.
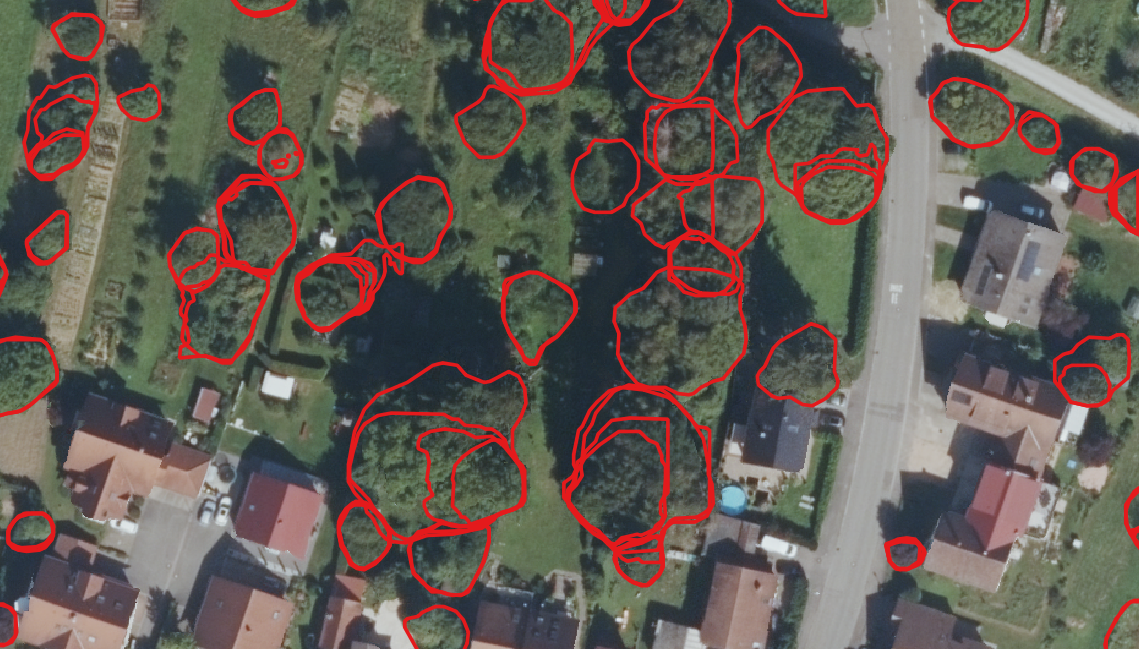
This all results in images like this:
and general predictions such as:
Generally we can see that urban single crowns can be separated very good, but thats about it, it fails at groups of trees, especially small or large trees and forests. This reflects the training data very well. In this case we did not believe hyperparameter tuning or architecture tweaks will result in easy solutions.
We also looked at the idea of annotating further data. This is hard for two reasons: 1) it is hard to annotated tree data as it is ambigous and cumbersome to see the separating for humans as well and 2) we assume, that we need a lot of training data, because the task is not that easy for forest environments.
Pretraining on forest data
Since we realized the models predictions have to get better, especially for forest regions, we need more training data or another training procedure. So we have two main point to worry about:
- Deal with bordering trees in a robust fashion, so increase separability.
- Increase Recall. At this point we think, that the attributes we can assign to each prediction are enough to filter out wrong crowns, so the focus of the model should first be to capture every single crown and later filter out the wrong one.
At this point we landed on a self-supervised pretraining task, that is given by analyzing height data and extract tree crowns from it. As we can see in the nDSM data, tree crowns are clearly visible, often there is just a relative difference to the pixels around the image. Our idea to extract polygons from it is pretty easy:
- Manually get images and height with no buildings or constructions inside (this could also be automated by using a index of shapes of buildings).
- Detect Maxima in this height data (with a given threshold) and by default classify them as a tree crowns, since we selected only tiles that match this condition.
- Make a Voronoi decomposition using the maxima points as control points.
- Apply a first mask to filter any below threshold points in the cells and a second mask to remove complete cells that are below the threshold to a relative high degree.

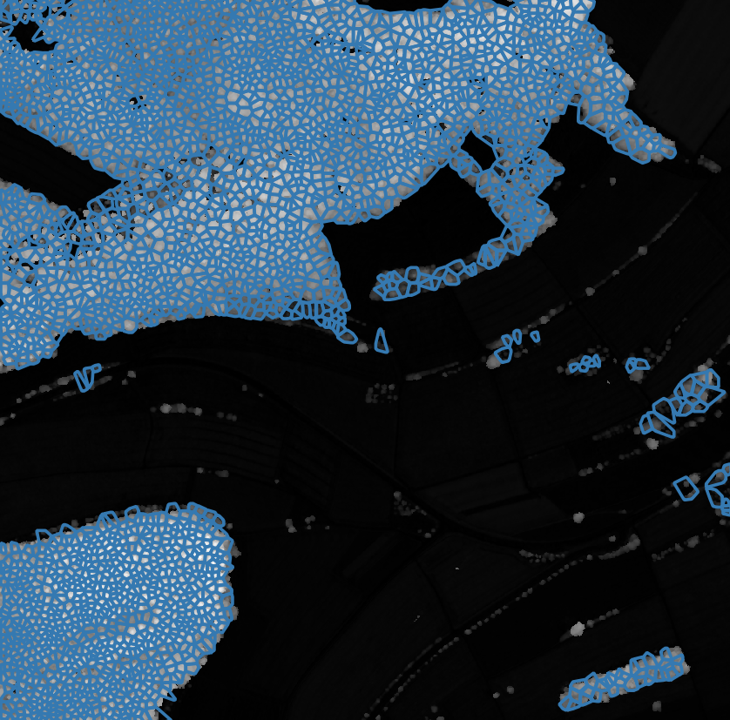
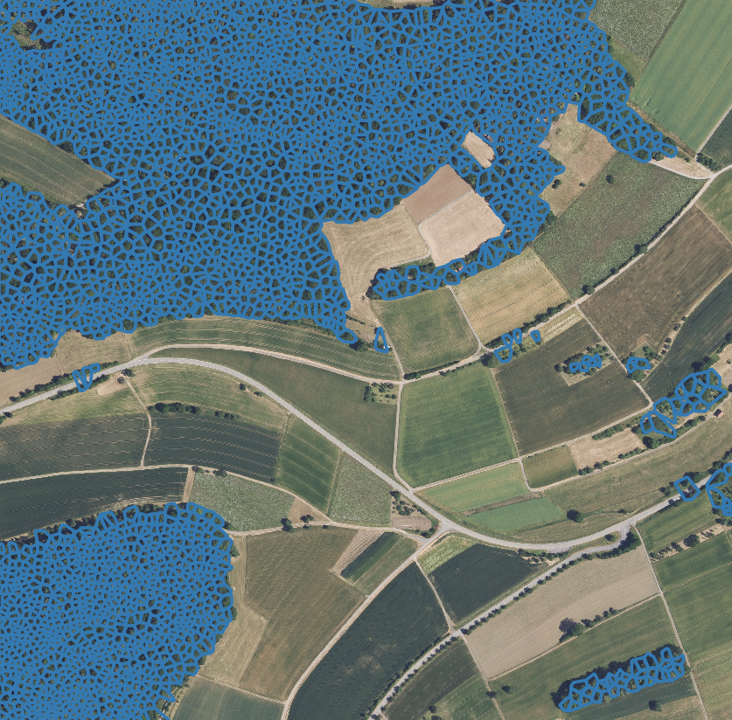
Example of the initial idea, with height data on the left side, the polygons on the center side and the rgb overlayed to the right side to illustrate the effect.
This idea is a good start but there are some serious points to optimize this, however we found the initial proposal to be sufficent:
- Finding maxima should be subject to the differences in the neighborhood: Coniferous forests, boreal forests and mixed forests have different surface properties and should be separated in different ways, there are ways to adapt the height finding algorithms for different environments.
- Change to better separtion algorithm, such as a marker controlled watershed algorithm. This allows for a clear boundary of the trees independent of the other ones. Another way would be to try to use separation algorithms that are based on the initial watershed segmentation and further segment it - using a simple edge detection segmentation or try the SAMGEO segmentation - which would work in some areas, but not every single one.
- Include other channels - such as nDVI data - for filtering and masking of the cells.
We then use this mechanism as autolabels to pretrain a ResNet model in the Masked R-CNN configuration. In our early results we see that the forest data does not need any finetuning to provide feasible results for our use-case and the current fine-tuning for urban areas suffice to register every tree with a good confidence.
Below you can see an illustration of the results:

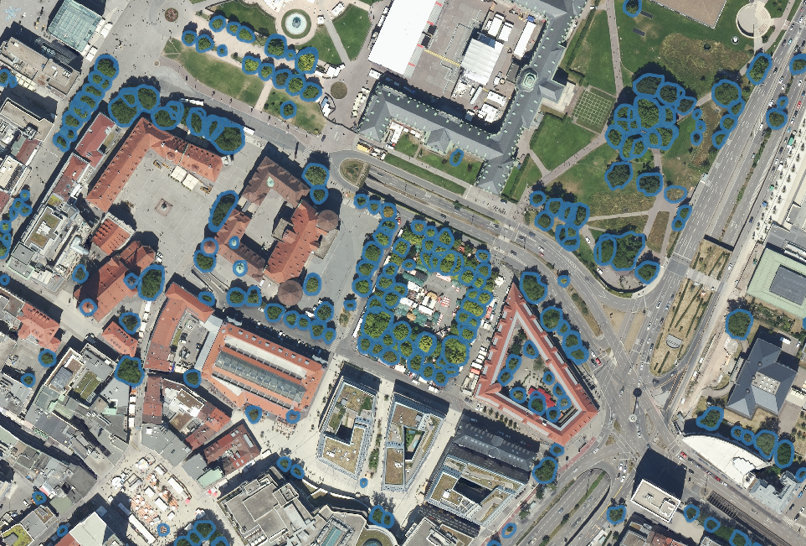
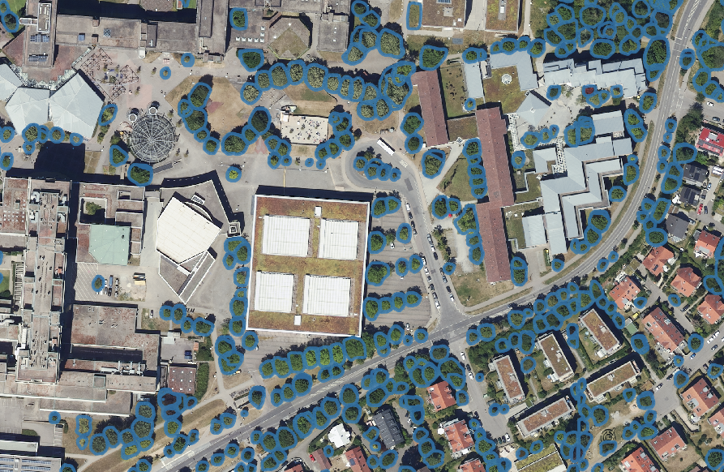

Four resulting inference examples using pretraining around Stuttgart.
Hierachical Recognition & Postprocessing
Now that the tree borders are separated reasonably well and we can identify theoretically every tree, our main problem now consists of getting the right shape per tree, so there are typically several predictions, that we have to filter. We first view every polygon isolated and exclude based on 1) Confidence Threshold, 2) Duplicates, 3) Height Threshold, 4) NDVI-Mean and Variance thresholds, and 5) Area. Lastly we filter polygons on containment in combination with previous methods, this is not tuned robustly but based on the experience with the predictions. The Rule based approach can be viewed straight in the code an is pretty straight forward.
Speed-Up
Since we recommend a very small tile size and also have to work with images with a lot of instances, we have to especially adress runtime issues. We optimize for runtime by:
- We only compute a tiling by file metadata and only view images at inference time, this assures a better parallelization and memory optimization.
- We allow to annotate single tiles of images with properties based on shapefiles in order to exclude them later for prediction -> We can use specific models for specific regions such as forests, cities, or agriculturual lands, without overhead at inference time
- We allow batching during inference with an independent parameter
- We optimized the addition of metadata to the inference points:
- Duplicate detection Since IoU-Computations of polygons, even only with overlapping bounding boxes, are not feasible, since there no good gpu accelerated libaries (options such as cuspatial or cupy exist), we only compare the IoU of the bounding boxes and the area of the polygons.
- Height detection Since again checking every point in the bounding box of a polygon for containment is too slow we approximate the shape of a tree with a circle (with a specific portion of the actual area) and use the heighest point in this circle.
- Containment We also check for containment by overlapping bounding boxes at first and then later check the actual containment.
This allows us to approximate roughly 1 square kilometer in a minute if parallelization is leveraged efficiently. Obviously this depends hugely on the area that is predicted.
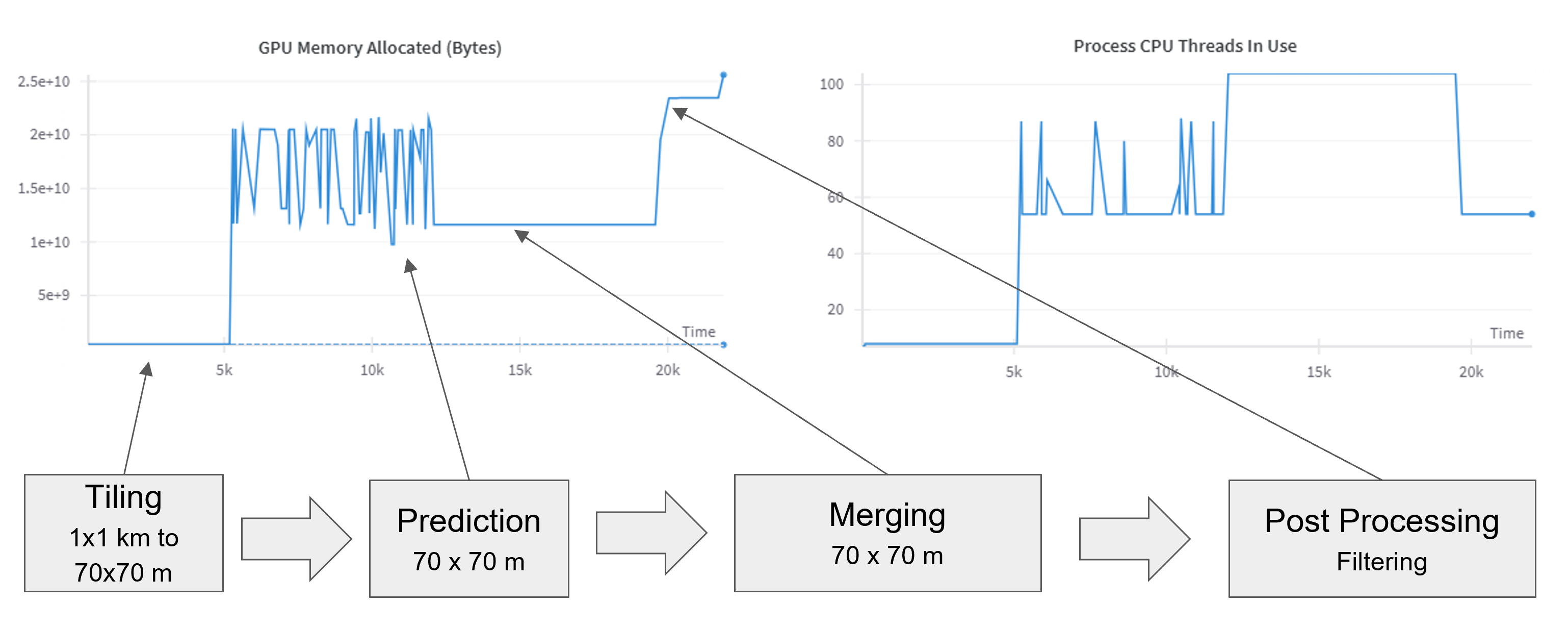
Example of inferring a set of images with GPU memory and parallelization, for the different phases of the pipeline.
Results & Comparison
There are several methods to evaluate a model, we start by looking at metrics, for this we annotate 3.25 square kilometers of different regions. Especially interesting here are the following parts:
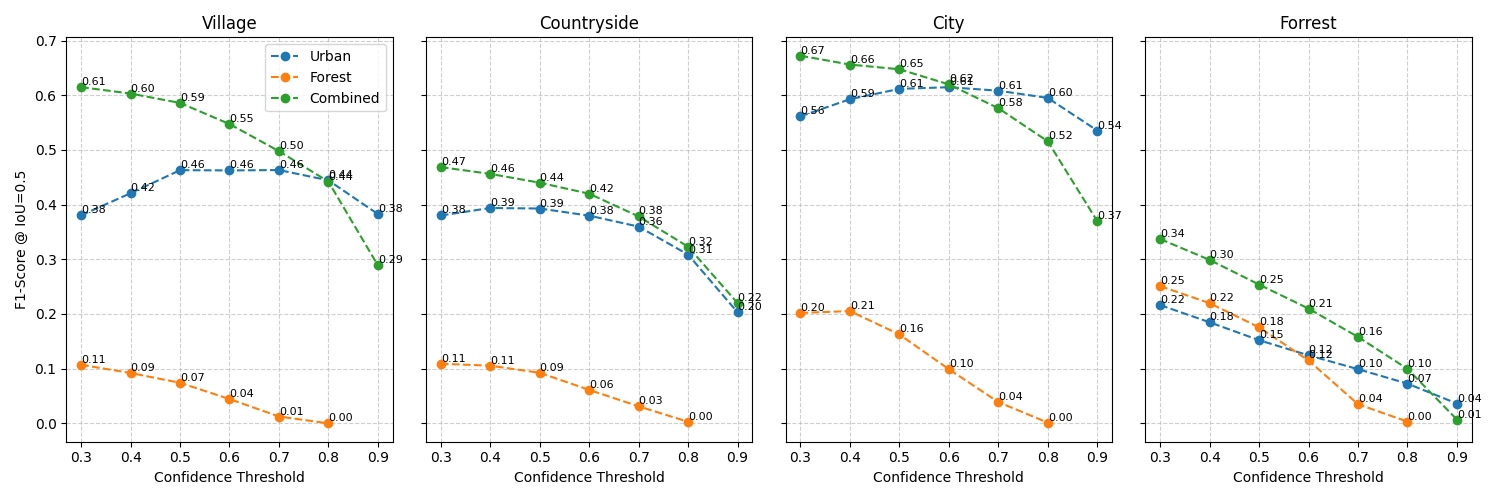
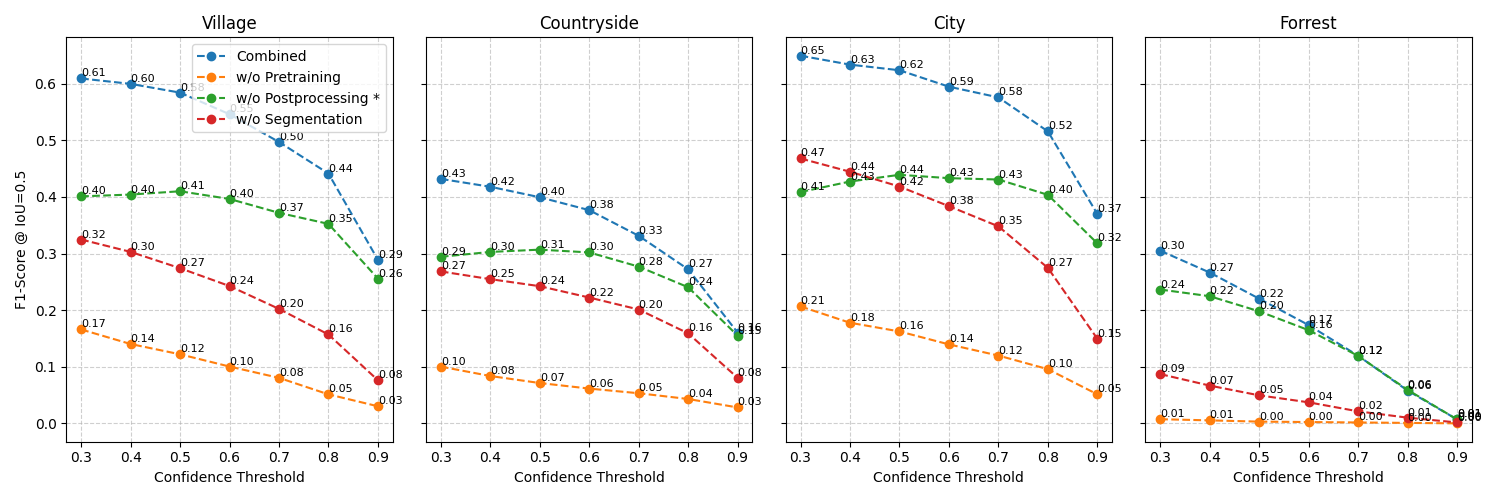
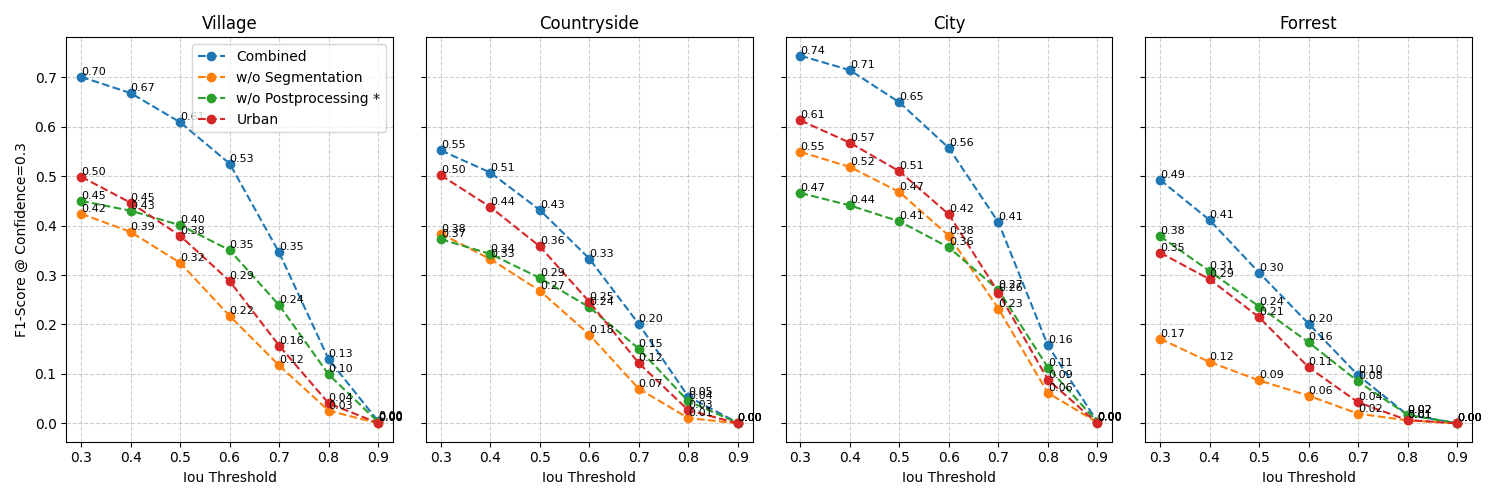
We have first a Comparison of the different models, secondly comparison of different measures and thirdly a comparison of shape accuracy.
As you can see while the pretrained model natively performs worst, it is responsible for the greatest advance in quality in the finetuned models. This reiterates the model’s downstrean benefit for a robust understanding. Furthermore the segmentation, from bounding boxes to actual shapes improves prediction secondmost. This is especially useful for city and village areas, as pretraining happens mostly there. Lastly the postprocessing has the smallest effect overall.
Besides metrics it is always important to take a look at the the current performance directly, I you want to use it I encourage you to take an image from the environment, you want to use it and try it for yourself. The code and installation instructions are available here. If you are just interested in the performance, you can look at the images below:
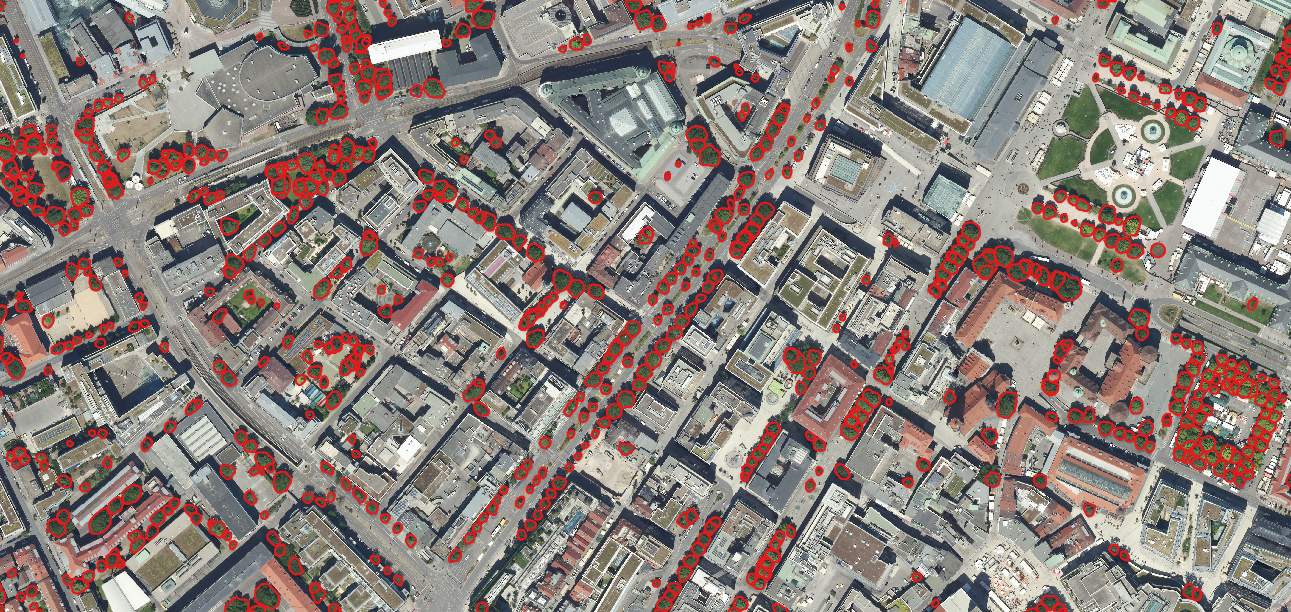
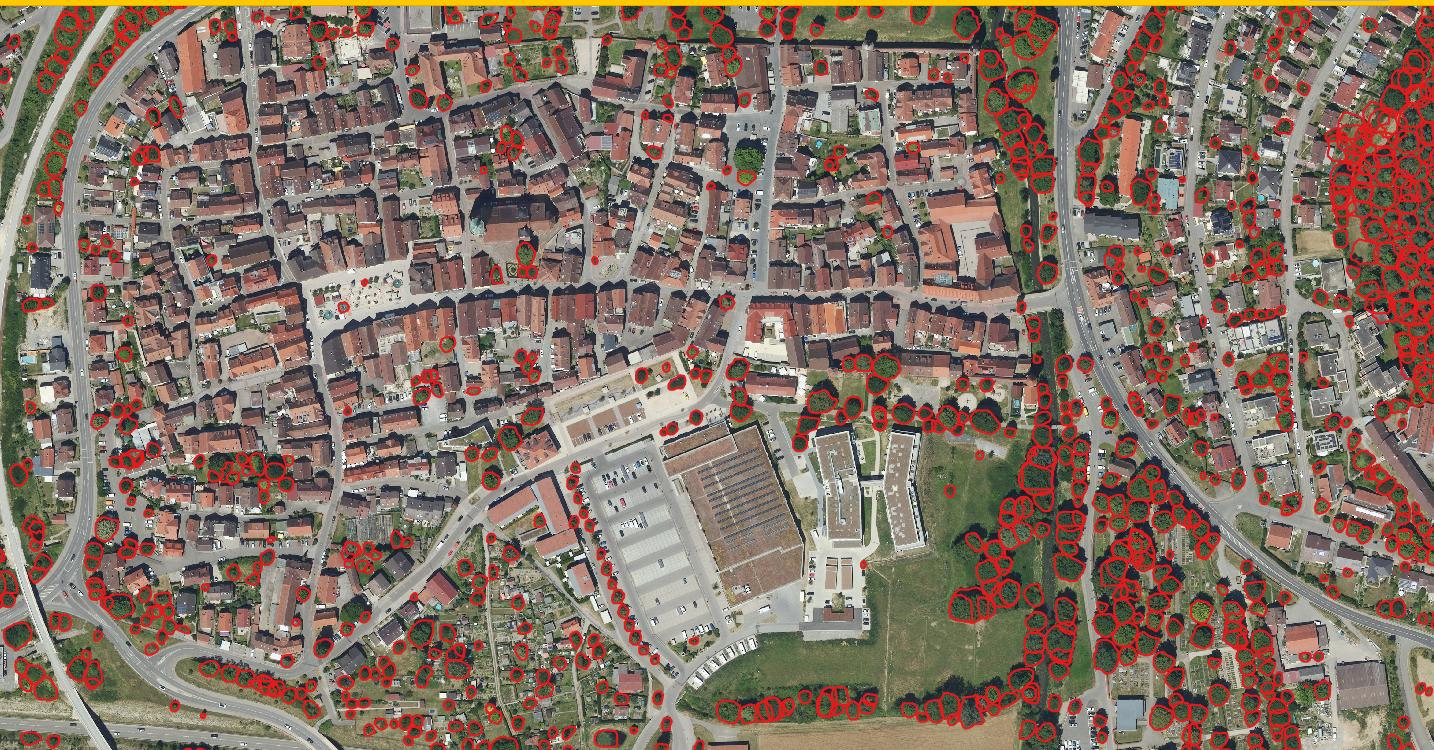


Final inference results of the framework in different regions.