
How to get Enterprise Knowledge into LLMs - An Overview
Published:
This article is part of a larger series of introductory AI tutorials for non-techies, written in German and auto-translated.
1. Introduction
Large language models such as ChatGPT, Gemini and DeepSeek have grown rapidly in recent years and completely changed the way we work with text. Companies have also quickly realised that they need to operate such models themselves in order to protect data. That is why ways have been developed to host LLMs privately and provide them securely within protected environments. This ensures that no sensitive data is leaked to the outside world. Internal information remains protected and documents, texts or images can be used without having to worry about data leakage.
If we operate the models ourselves anyway, we can also provide them with internal knowledge and context about the Regional Finance Office and our areas of work.
LLMs originally learn only from public internet data, general data sets and previous chats. However, our wikis, cloud systems and folder structures contain a wealth of internal information that would be much more valuable. This blog post provides an overview of technologies that can be used to harness internal knowledge in order to obtain better and more reliable answers. When it comes to legal texts or regulations, it is crucial to reproduce information accurately. LLMs often only have a rough understanding of this. To provide correct answers, they need the ability to look up and verify knowledge, just like humans do.
In the first step, we look at how models can be directly adapted to permanently incorporate knowledge into the model. We then consider methods that allow a model to look up information when needed. Finally, we provide a brief overview of new approaches that are promising but have not yet become fully established.
The article deliberately uses ‘handwaving’, i.e. without many technical details, in order to convey a basic understanding. The explanations are intended to make the ideas understandable without being completely mathematically correct. Please note that this article was written in November 2025 and many of the technologies described are evolving rapidly.
2. Writing Knowledge into the Model
The most direct way to equip a language model with internal knowledge is to store this knowledge directly in the model itself. This is the most elegant option, but also the most demanding, as training neural networks is extremely computationally intensive and involves complex mathematical processes.
In this chapter, we first explain what training involves for large models, then we look at how existing models can be improved and adapted to specific domains, and finally we present methods that make training more efficient without compromising accuracy too much.
Pre-Training – Why only the big Players can do it
Large language models consist of neural networks with billions to trillions of parameters. Pretraining requires enormous computing power: often hundreds of GPUs or TPUs over many weeks. Only a few institutions in Germany have the necessary infrastructure, such as AI-Fabrics in Stuttgart and Jülich. In addition to computing power, the database is also an obstacle. Large models are trained with gigantic datasets such as Common Crawl or Books1/Books2, whose legal status in Europe is still under discussion. Just recently, the first landmark ruling on the use of song lyrics in language models (GEMA vs. OpenAI) was handed down, but it is not yet legally binding.
Pretraining Process
Pretraining takes place in several phases, each of which teaches different skills:
- Self-supervised learning
In this phase, the model solves simple tasks, such as filling in gaps in sentences or continuing texts. The aim is to learn language structures: word types, syntax and simple semantic relationships. Here, the model learns which words typically occur together and which sentence structures make sense. - Curated data sets and sample conversations
In later phases, data that promotes the desired skills is used in a targeted manner. This includes structured texts, FAQ data and dialogue examples. The model learns to understand more complex and abstract relationships and to generate responses in a specific style. - Alignment Finally, the so-called ‘alignment’ takes place, in which human annotators control the behaviour of the model. The aim is for the model not simply to reproduce content from the internet, but to respond in a reliable, fact-based and helpful manner.
The alignment consists of three sub-steps:
- Supervised fine-tuning: Sample questions and answers are used as training data.
- Answer ranking (reinforcement loop): The model generates multiple answers, which are sorted by quality and used for training.
- Reinforcement learning through feedback: Another model or humans evaluate individual tokens and sentences, teaching the model to optimise word choice and content.
Note: Pre-training is probabilistic. This means that after training, the model uses probabilities to predict the next answer. Therefore, human corrections in alignment are crucial to ensure consistency and factual accuracy.
It is also important to mention that scaling LLMs to a smaller model that we could train ourselves would not work better than using an existing LLM, unless special methods in the field of distillation are applied. The AI boom was triggered by the discovery of properties within LLM training scaling, and currently, good compact models are still an open problem.
Fine-Tuning – ‘baking in’ Domain Knowledge
Domain-specific fine-tuning is the final step in the training process of an LLM, during which alignment also takes place. While pre-training gives the model a general understanding of language – i.e. grammar (syntax) and meaning (semantics) – it does not yet know the exact facts of a particular subject area. For example, it does not know which laws apply in the financial sector, which internal guidelines are relevant, or what typical processes look like in a government agency.
During fine-tuning, the model is specifically trained on such specific content. A typical approach is to analyse relevant documents – laws, regulations, manuals or internal guidelines – and generate training data from them. To do this, a suitable question-answer combination is automatically created from each sentence. Example: A question such as ‘What requirements must be met for approval X?’ could be derived from a paragraph, and the model provides the answer from the sentence. Training is iterative: the model answers the generated questions and the answers are evaluated. Deviations from the correct solution are penalised, while correct answers are rewarded. In this way, the model learns to accurately reflect the rules and facts of the subject area. Despite the reduced amount of data compared to pre-training, fine-tuning remains challenging: the model still has to store and calculate many parameters simultaneously. Unlike in normal use (inference), every intermediate step in the network must be logged here so that the gradients can be calculated. These gradients show the model how to improve in the next iteration – a central component of the learning process. Another important point is that fine-tuning specifically shapes the model’s behaviour: it not only learns facts, but also how to react in certain situations. In the financial example, this means that the model not only quotes the correct paragraph, but also adheres to the response style, for example, factual, precise and comprehensible. This creates a model that is truly usable for the specific application without users having to constantly check its accuracy.
In summary: Fine-tuning is the step in which a model transforms from a general language understanding model into a specialised assistant. It stores domain-specific knowledge in its parameters, learns the rules of a subject area and can respond specifically to tasks and questions relevant to that area. At the same time, training remains resource-intensive and requires careful planning to ensure that the model learns in a stable and reliable manner.
Parameter-Efficient Fine-Tuning (LoRA, Adapters)
A common idea is to make the fine-tuning of LLMs more efficient and resource-friendly without having to retrain the entire model. Two of the most practical methods are Lower-Rank Adaptation of LLMs (LoRA) and Parameter-Efficient Training with Adapter Layers. Both approaches have in common that not all parameters of a model are adjusted, but only the relevant ones. This significantly reduces memory and computing costs, while still allowing adaptation to specific knowledge.
Neural networks consist of many layers connected in series, each of which learns different tasks. The lower layers recognise simple patterns, such as syntax, word forms or sentence structures. The middle layers connect these patterns to form more complex relationships, while the upper layers capture abstract concepts and higher-level relationships. This principle can be directly applied to LLMs – however, the layers here are significantly larger, often numbering several hundred, and processing complex linguistic relationships requires billions of parameters. It follows that in order to specifically incorporate domain-specific knowledge, the high-level features in the upper layers must be adapted first and foremost. The lower layers remain largely unchanged, as they already represent basic language competence.
LoRA - LOW-RANK ADAPTATION
LoRA (Hu et al.) is not about changing all the weights of a model, but also not just selected individual ones. Instead, an additional small matrix is trained in parallel with the existing weights, which maps the necessary adjustments. The idea behind this is that in a large layer, only a few parameters are actually relevant for a specific task. Mathematically, the difference between the initial model and the desired adjustments is represented as ΔW = BA. Here, A and B are small matrices that together approximately represent the changes in the large weight matrix. This approach allows a lot of knowledge to be stored in a small amount of data, significantly reducing memory and computing requirements. During training, only the gradients of A and B are calculated and stored. This eliminates the need to track the entire parameter space, which drastically reduces memory requirements. After training, the new weights are calculated by W’ = W + ΔW. LoRA was originally only applied to the attention layers, as these contain the most parameters and are particularly memory-intensive. In combination with extensions such as QLoRA or IA³, LoRA can be used effectively for parameter-efficient fine-tuning (PEFT). This means that even mid-size models can be adapted to standard GPUs such as the Nvidia A100 without having to completely re-train the model.
](/images/No-Tech-Articles/lora.png)
Another method for parameter-efficient fine-tuning is the use of so-called adapter layers (Houlsby et al.). Adapter layers are an elegant way to efficiently adapt LLMs to specific knowledge without having to retrain the entire model. The basic idea is to insert small, trainable modules between the existing layers while leaving the original weights of the model unchanged. This does not affect the general language understanding that has already been learned. Only these new adapter layers are adjusted during the training process. They are deliberately smaller than the original layers and act as flexible buffers in which new knowledge, such as domain-specific rules or internal guidelines, is encoded. The model thus learns to respond correctly to technical questions without losing its basic language skills. This method offers several advantages. It conserves resources, as significantly fewer parameters need to be trained than with classic fine-tuning, and it ensures stability because the base weights remain unchanged. At the same time, it allows for modularity: adapters can be developed specifically for certain tasks or subject areas and later replaced or expanded to reflect changes in regulations or processes. At the same time, the use of adapters requires careful planning. Their placement within the layer structure and their size significantly affect performance. Too many or incorrectly positioned adapters can reduce efficiency or even compromise the stability of the model. However, if this is taken into account, the method enables very flexible and scalable fine-tuning that specifically optimises LLMs for specific tasks without the high cost of complete retraining.
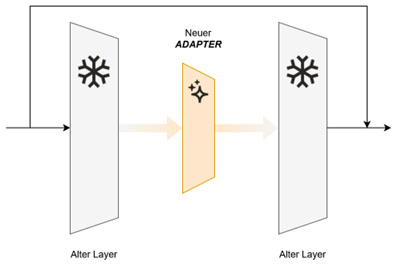
3. Storing Knowledge alongside the Model (RAG)
In the previous chapter, we saw how knowledge can be built directly into a model. However, this method still has some limitations. Every time new information is added or existing data is updated, the model would have to be completely retrained – a very costly and time-consuming process. In addition, the training is probabilistic: the results can change slightly, which is why a new check is necessary after each adjustment.
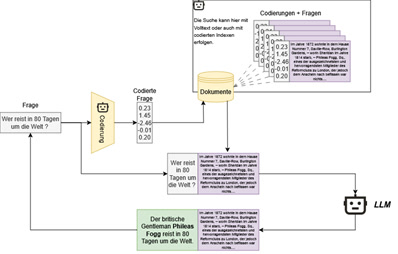
An elegant alternative is to store the knowledge beside the model and only provide it as context when needed. This approach is known as retrieval-augmented generation (RAG). Unlike classic fine-tuning, the aim here is not to change the parameters of the model itself, but to provide the model with additional information that is retrieved when answering a question. You can think of it as a kind of ‘intelligent reference work’ available to the AI. The principle is simple and comparable to human behavior: when we don’t know something, we look it up—in a book, a database, or online. In the same way, a RAG system can find relevant documents, facts, or data sets and provide them to the model as context. The model treats this information as part of the question and can generate accurate answers based on it. This allows models to remain flexible, utilize current knowledge, and significantly reduce the effort and cost of complete retraining. RAG thus combines the power of large language models with the timeliness and reliability of external information sources.
Simple RAG – Get facts instead of Hallucinating
RAG was introduced in 2020 by Lewis et al. and has since been considered one of the simplest methods for automatically making non-public data usable for AI models. The basic idea is that a system not only accesses its internal knowledge, but also retrieves relevant documents or information in real time to provide more accurate and verifiable answers.
In principle, RAG systems can be divided into three steps: retrieval, augmentation, and generation.
- First, the retrieval step finds suitable documents or data records that could be helpful in answering a question. The system can access all possible sources: databases, internal document collections, knowledge graphs, or external search APIs. The search is performed either on the basis of normal text or by means of so-called embeddings. Embeddings are a numerical representation of texts in a multidimensional space, in which the similarity between documents is described by the distance between the vectors. This allows the model to recognize semantically similar content, even if the exact words are different.
- In the augmentation step, the documents found are added to the original question. The model must be able to distinguish which information is part of the question and which comes from external sources. This ensures that the additional content serves as context and is not mixed with the actual user question.
- In the final step, generation, the LLM uses both the original question and the added documents to formulate an answer. The model can often provide evidence or sources for its answer, which increases traceability and allows the user to delve deeper into the documents.
An interesting effect of RAG is that the focus of AI use is shifting: LLMs are increasingly being used to find relevant documents independently, while the actual answer is less important. At the same time, new requirements are emerging: high-quality documents with appropriate content must be reliably identified. This is precisely what embeddings are used for. They are often also created by AI models, so that the relevance of the documents to the specific question can be automatically evaluated.
Nowadays, RAG is typically operated with a number of enhancements that increase precision and make the context more usable. These improvements include dense retrieval models as embeddings, neural reranking, and multi-hop retrieval. Furthermore, a class of modular RAGs in particular has established itself as a strategy. Here, hybrid retrieval strategies with different encoder types (sparse+dense) are used, with flexible use of various tools, APIs, databases, and pipeline components that perform different retrieval, generation, and validation steps for individual queries.
Modular RAG can also include components such as visualization, routing, and fusion. Depending on the query, i.e., complexity, documents found, and configuration, the RAG system is flexible and selects the path with the most likely best output result.
Another honorable mention is Graph RAG, which allows you to display context using nodes in a graph. Graphs offer the possibility of being more flexible than linear documents or individual contexts; they are an incredibly powerful but currently very complex approach to making knowledge available. However, knowledge graphs are such a broad topic that we do not want to go into further detail here.
Agentic RAG – the Model plans its Research
Agentic RAG differs from the previous models particularly in terms of autonomy and self-image. In an overview, Singh et al. presented four central behavior patterns that are characteristic of agentic systems:
- Reflection An agent evaluates a response based on the question, the response itself, the available resources, and its role. For example, a smaller LLM can be trained to generate an initial response and then evaluate it. The system then decides whether to accept the response and pass it on to the user or reject it and revise it. Reflection is not stored directly in the LLM, but is mapped as a feedback loop in the overall system.
- Planning Planning can be done in various ways. One option is prompt chaining, in which a complex query is broken down into several individual LLM subtasks. This allows multi-step or complex queries to be processed efficiently. Other planning methods include routing to specialized LLMs when expertise from specific domains is required. In general, the LLM plans the steps necessary to answer the query.
- Tools Some agents use special APIs to interact with programs, databases, the Internet, or other models. One example is MCP, which provides a standardized protocol to which various services can be connected. Administrators must manage the integration and access rights of the systems.
- Collaboration Multiple agents can be interconnected. This allows experts to be consulted, answers to be verified, different solutions to be tested, or plans to be coordinated. Collaboration makes it possible to solve complex tasks more efficiently by combining multiple perspectives and skills.
Overall, it can be said that agents are extremely powerful and offer functionalities that pure LLMs cannot replicate. At the same time, however, it becomes more difficult to understand exactly how an answer is generated, and control over the system remains challenging.
A particularly important aspect is the degree of autonomy of the agents. It remains unclear what rights and scope of action should be granted to AI. Initial practical applications lie in the area of simple tasks such as ordering food, managing calendars, or taking notes during meetings. It is already possible to give smaller LLM agents limited permissions, such as accessing the calendar, automatically accompanying meetings with links, and creating summaries as “notetakers.”
4. Memory Systems
Since LLMs use their entire knowledge base for every query, this is both expensive and not very up-to-date. Retrieval-augmented generation (RAG), on the other hand, searches for specific documents but does not independently create a coherent context. There is therefore still a need for a system that can independently derive context so that a language model can remember tasks, requirements, purposes, and goals. In this chapter, we look at an example of how memory could be natively integrated into language models in the future. Here, it is particularly important to focus on the basic ideas and building blocks without getting lost in technical details, as the solutions may change significantly before commercial release.
Semantic memory
Semantic memory stores facts such as place of work, favorite food, or eating habits and can be easily fed into the neural network via a prompt. LLMs often organize such information as collections of facts, for example in the form of triples. After each interaction, the conversation is analyzed and new information is merged with the existing data. ChatGPT, for example, supports semantic memory. However, a key challenge in its use is the precise extraction and merging of information, especially when data from multiple sources or sessions converge.
Episodic memory
Episodic memory captures individual “episodes,” i.e., specific interactions. This works best when summaries of previous conversations are incorporated into the context of the current question. The main problem here is that conversations with AI can become very extensive, requiring the model to find relevant information in a large volume of text—a classic “needle in a haystack” problem for LLMs.
Procedural memory
Procedural memory captures role understanding and action knowledge. It answers the question: “What do I do in this situation?” For example, it includes processes such as getting up, preparing breakfast, making coffee, or brushing your teeth. In LLMs, this knowledge is usually stored implicitly in the weights through training, allowing the model to apply similar action patterns in new situations.
Memory Mechanisms - Titans Explained
In this section, we would like to present an example mechanism and break it down in detail to answer the question: How can you implement a memory that can store both facts and data from previous conversations and a comprehensive overview of company-wide documents? At the same time, the architectures in this area are not yet mature enough to be available as finished products. Nevertheless, an overview of new technologies can still be interesting—especially for readers who have a certain technical interest in this area.
First, we translate the concepts of semantic, episodic, and procedural memory into the categories of context memory and long-term memory. Irrefutable facts from semantic memory are transferred to long-term memory. In our case, these include, for example, dispositions, legal texts, or user profiles (role, age, favorite programming language, etc.). Procedural memory remains stored as behavior in the classic model weights and is not considered further here. Episodic memory, on the other hand, is transferred to contextual memory, as it represents the context of a specific interaction from the LLM’s perspective.
Google Research presents the Titans architecture in an article. The underlying concept is called “learning to build memory at test time” and is a slight modification of the already known approach “learning to learn at test time”, which was previously developed as a higher-level research paradigm in the context of active learning.
For contextual and persistent memory, the Titans architecture is based on the following equation: $M_t \leftarrow M_{t-1} + S_t$ with $S_t \leftarrow \theta_t S_{t−1} \eta_t − \theta_t \nabla \ell (M_{t-1};x_t)$.
At first glance, the equation seems complex, but it can be explained relatively simply: $M_t$ is the memory at time $t$, and $S_t$ denotes the “surprise” that occurs at that moment. Put simply, memory is only updated when new information is surprising. However, this poses a challenge: much information is surprising but not really relevant or informative. Therefore, surprise must be regulated—only particularly informative surprises should be stored. The factor $\eta_t S_{t−1}$ represents the “normal” surprise that has already occurred, while the term $\nabla \ell(M_{t−1};x_t)$ describes how different the new facts are from the information already stored. If the difference is large, we store the input; if it is small, the memory remains unchanged. It is striking that the update term of the Titans architecture closely resembles the classic learning process of neural networks. The term “learning” is deliberately used ambiguously here—both for learning before and during inference—to emphasize this analogy. However, this requires some attention when reading, as there is no established alternative term.
From this mechanism, the authors of the Titans article derive three architectures, two of which are illustrated here. The short-term memory in the following graphics refers to the normal context window of the current conversation in the model.
The first model, the Memory-as-a-Context Model, works by continuously building up short-term memory during a conversation. After each interaction, the long-term memory is updated based on the responses. After a certain period of time, short-term memory—i.e., the details of the conversation—is pushed into the background, while long-term and semantic memory are given greater consideration. Then a new short-term memory begins, which is placed at the forefront again.
The second model, the Memory-as-a-Gate Model, consistently adds semantic and fixed knowledge to the end of the context, so that the current query becomes increasingly distant from the original knowledge store as the conversation progresses. An additional component—long-term memory—is integrated between the knowledge base and short-term memory. New and interesting information is given priority, while less relevant or older data gradually fades into the background.
The following diagram shows a schematic representation of the architecture. The red area represents factual knowledge, similar to that stored in RAG, but in a neural memory within the weights of the network. This information is independent of the current query and is usually very relevant. The blue blocks show how the specific query is processed. In the MAC architecture, the query context, i.e., the short-term memory, is enriched with both long-term information and factual knowledge before a selection is made. The long-term memory is then updated. In the MAG architecture, on the other hand, the selection is made only from the factual knowledge and the current query window, while the long-term memory is queried separately.
Below the graphic, you can see how the information is “presented” to the LLM, i.e., where each piece of information is placed in the context window.
| Memory As a Context (MAC) | Memory as a Gate (MAG) | |
|---|---|---|
| Architecture | 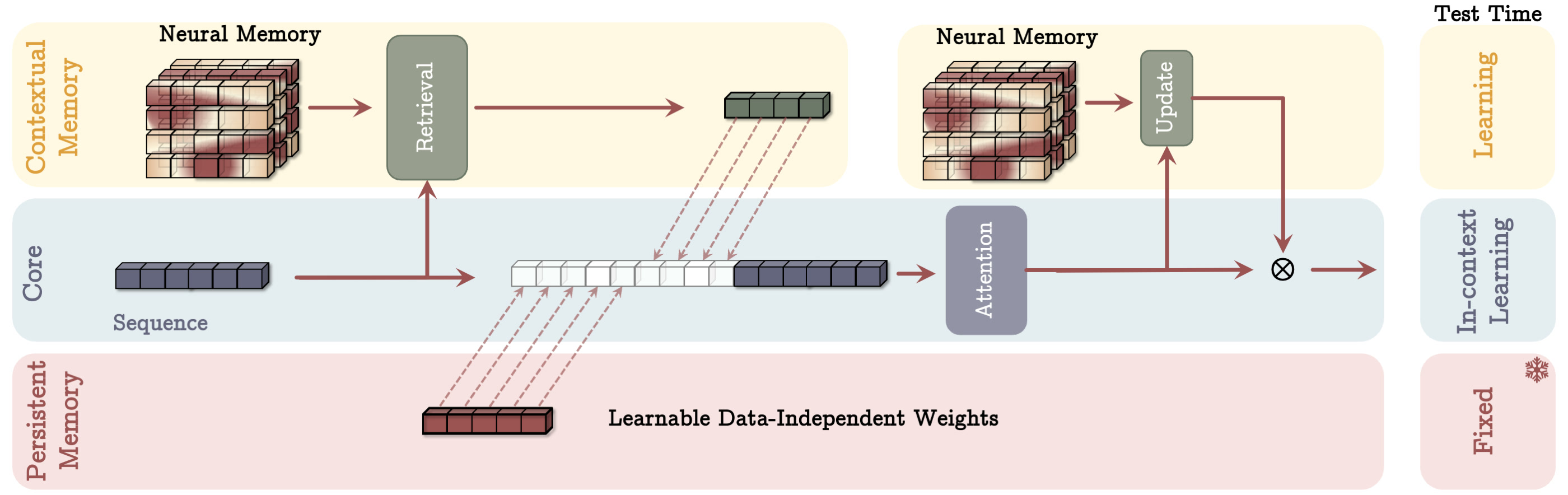 | 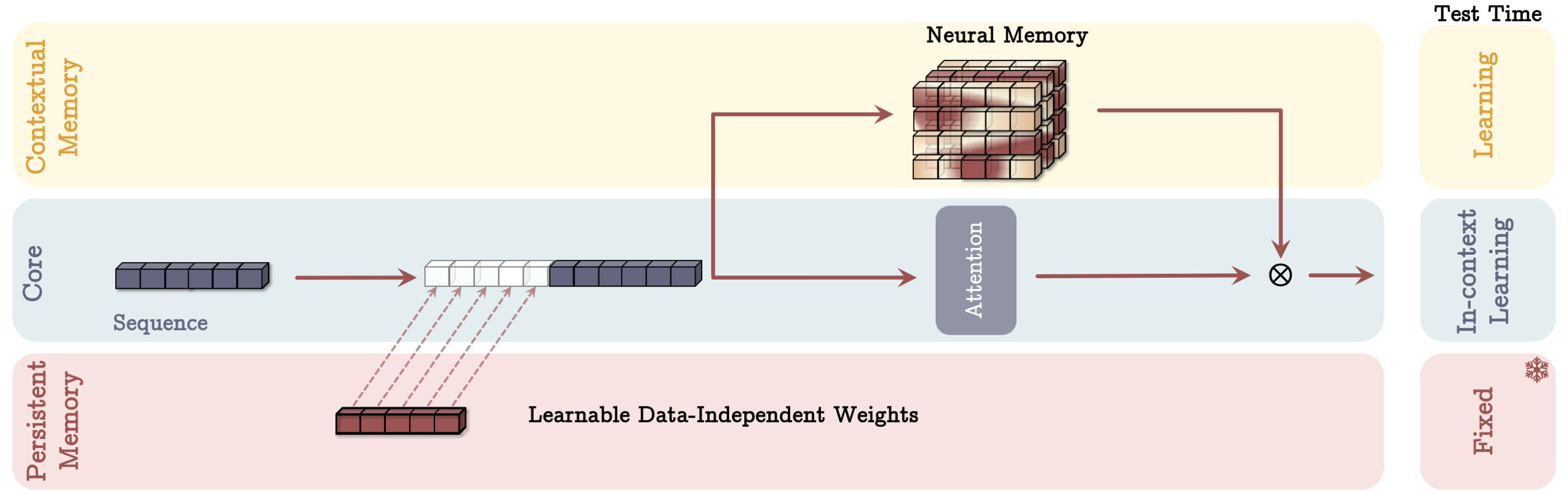 |
| Attention Context | 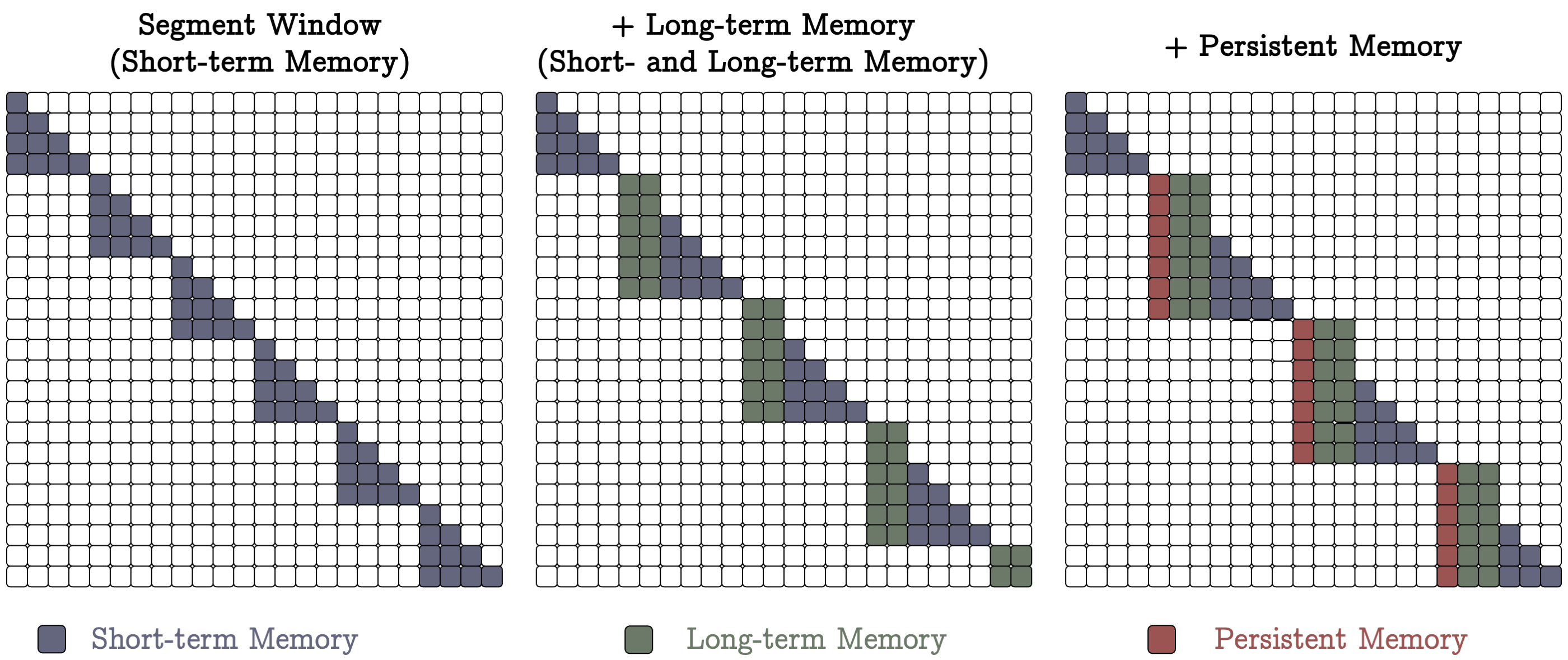 |  |
Another important aspect besides the selection and use of information is the forgetting of less relevant data. New information should be used preferentially, while old, less relevant, or potentially inaccurate information should be relegated to the background.
This can be represented by a simple mechanism: $M_t \leftarrow (1-\alpha_t)M_{t-1}+S_t$ with $\alpha_t \in [0,1]$. Old knowledge is automatically given less influence than new information. The value of $\alpha$ can be used to control how much weight is given to old knowledge and how much priority is given to new knowledge.
Since we have already gone into more technical detail here, here is a summary of the key takeaways:
- In addition to retrieval-augmented generation, other methods are being developed that enable more natural interaction with voice assistants.
- Such systems have advantages: User-specific data can be extracted, stored, and used in a more targeted manner.
- A good memory system must perform many tasks: updating, selecting, forgetting, and correctly positioning information.
- Memory can be divided into different contexts, similar to humans. In the future, language models will also be evaluated according to these abilities:
- Episodic, semantic, and procedural memory
- Short-term, long-term, and persistent memory
- So when an LLM suddenly “knows a lot about you,” it’s not magic, it’s mathematics.
Memory Mechanisms – What Else is there?
Of course, the method described in the previous section is not the only way to incorporate memory into a language model. Below are a few other approaches and concepts to provide a rough classification:
Short-term memory
Everything that only exists during a single task or session falls into this category. This includes, for example, the context window, which contains the chat history of a language model and thus stores information about previous questions and answers. This also includes the so-called working memory, such as chain-of-thought or “scratchpads.” These mechanisms enable the model to record intermediate steps that are not directly contained in the question or answer but are relevant for finding the answer. Agent states, i.e., the current status of an agent, can also contain short-term information that is used to process a request.
Long-term memory
This category includes information that is stored across sessions. This includes user profiles, which summarize facts from previous interactions, as well as external RAG, i.e., external databases that contain past conversations or relevant documents. Memory agents are often used to manage these memory structures, frequently in combination with RAG.
Persistent memory
Persistent memory mechanisms are stable and do not change automatically. These include model weights, which store basic behavior, rules such as grammar, basic knowledge, and style. Persistent user profiles also fall into this category if the information is not processed directly by the model. Finally, there are system prompts, i.e., unchangeable instructions or role definitions that are included in every request and determine the behavior of the model.
5. Long Context Windows
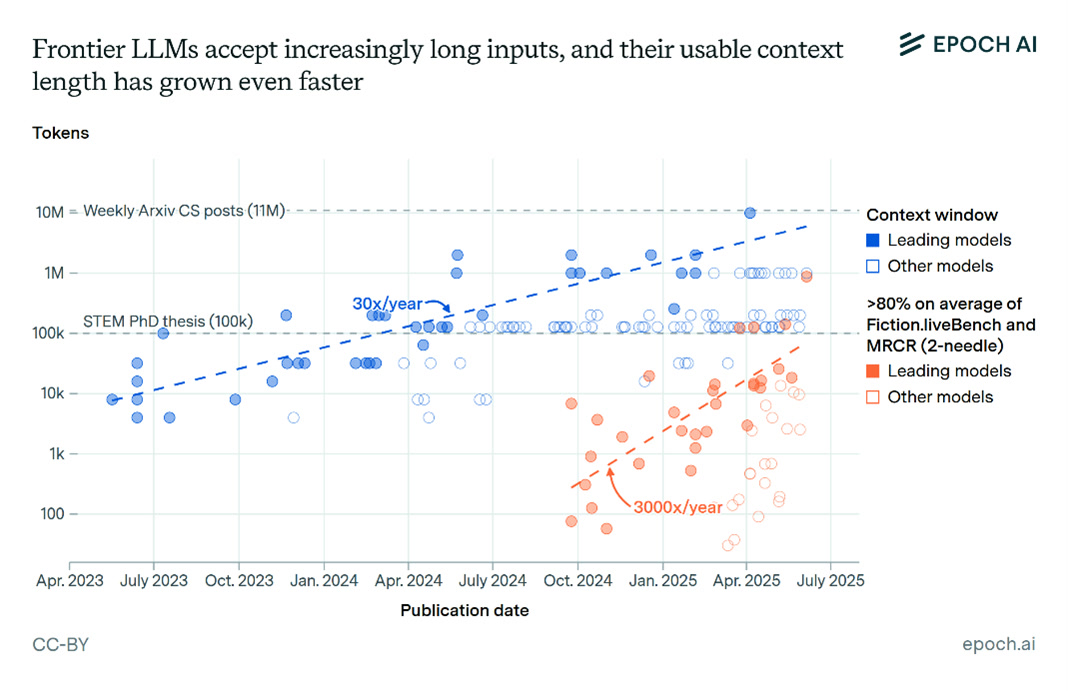
An LLM is always addressed with a context window. This contains, for example, information from the previous conversation, additional documents, or the system prompt. The goal is to expand this working window so that all relevant information can be provided at the same time. This is particularly useful when working with large documents and wanting to include all information in the processing. Large providers such as Google with Gemini or Alibaba with Qwen rely heavily on such large context windows.
However, long context windows are more of a quick-and-dirty solution. Although they work in principle, they increasingly cause problems and do not yet scale as well as is often advertised by providers. Studies show, for example, that above a certain length, semantic connections are lost and the performance of the LLM suffers under the load of the extensive context.
6. Summary
In this article, we looked at how LLMs can be enriched with concrete domain knowledge, i.e., specific expertise from the respective field of work. First, we considered the possibility of embedding knowledge directly into a model. Special fine-tuning methods such as LoRA are particularly suitable for this. However, this approach is generally more complex and less flexible. We then examined how knowledge can be embedded directly into the LLM query, i.e., via retrieval-augmented generation (RAG). This approach is significantly simpler and more flexible. Extensions such as Agentic RAG are also characterized by reflection, planning, tool use, and collaboration, which enable LLMs to work more independently and adaptively. In Chapter 4, we looked beyond the horizon and examined specific memory systems. These systems make it possible to store, select, forget, and use information in a targeted manner. Basically, three main types of memory can be distinguished: short-term, long-term, and persistent memory. Finally, we took a look at practical applications and considered long context windows. They offer a simple way to incorporate large amounts of information into processing and are currently showing rapid success, but they do come with some challenges, which is why they were only discussed briefly.
In the future, several trends will further change the use of LLMs in a business context. Active learning approaches could enable models to learn specifically and efficiently from user feedback or new data without having to undergo complete retraining. Explainable AI will become increasingly important as companies need traceable and auditable decisions, especially in regulated areas such as finance or law. At the same time, agent networks with greater autonomy will become more relevant, enabling them to plan, research, and collaborate independently, while remaining constrained by clear control mechanisms. At the architectural level, neural memory structures such as Hopfield networks or Boltzmann machines could regain attention as they can efficiently store and retrieve long-term patterns and relationships. Together, these developments promise more flexible, powerful, and transparent systems that dynamically leverage corporate knowledge while remaining robust and traceable.
Thank you for reading and for your interest in this topic. I hope the insights were inspiring and gave you an impression of how AI systems can be examined in more detail and what is currently being worked on!